🐉 Engenharia Reversa em Aplicações de Baixo Nível
 Assembly is NEEDED
Assembly is NEEDEDeverything is open source if you can reverse engineer.
Exemplo: A Análise de Funções
1. Função Matemática:
Considere uma função matemática simples, como
$$ f(x) = x^2. $$. Essa função pega um número \( x \) e retorna seu quadrado.
2. Entrada e Saída:
$$ x = 3 => f(3) = 3^2 = 9. $$então, a entrada é \( 3 \) e a saída é \( 9 \).
3. Engenharia Reversa: Agora, suponha que você tenha apenas a saída (o resultado)
$$ f(x) = 9. $$e deseja descobrir a entrada original. Isso é similar ao que fazemos na engenharia reversa. A tarefa é encontrar o valor de \( x \) dado
4. Resolvendo a Equação: Para encontrar a entrada, você precisa “reverter” a função. Neste caso, você resolveria a equação:
$$ x^2 = 9 => x = \sqrt{9} \Rightarrow x = 3 \text{ ou } x = -3. $$Para encontrar \( x \), você tira a raiz quadrada de ambos os lados:
Aqui, você foi capaz de descobrir os valores de entrada que poderiam ter gerado a saída.
Engenharia reversa de software é como resolver uma função matemática: você começa com a saída e trabalha para trás para descobrir a entrada. Esse processo pode envolver a análise do código-fonte, observação do comportamento do software ou o uso de ferramentas específicas para inspecionar o que está acontecendo por trás das cenas, assim como resolver uma equação matemática requer conhecimento sobre as operações que transformam a entrada na saída.
Etapas do processo de Compilação
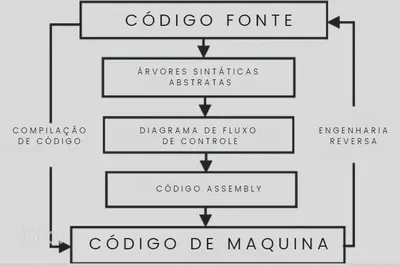
Fonte: O Autor
A imagem acima, mostra de forma simplificada como funciona o processo de compilação código-fonte até o código de máquina. Entender isto é entender como podemos inverter esse processo na engenharia reversa
Código-Fonte
O código-fonte é o texto escrito por programadores em uma linguagem de programação de alto nível. Aqui, utilizo C como exemplo:
Exemplo (C):
int soma(int a, int b) {
int resultado = a + b;
return resultado;
}
Árvore Sintática Abstrata
A AST é uma estrutura de dados que representa a estrutura hierárquica do código-fonte. Ela é gerada após a análise léxica e sintática pelo compilador.
Exemplo (AST para o código acima):
FunctionDefinition:
Type: int
Identifier: soma
Parameters:
Parameter:
Type: int
Identifier: a
Parameter:
Type: int
Identifier: b
Body:
Declaration:
Type: int
Identifier: resultado
Init:
BinaryOperator:
Operator: +
LeftHandSide: a
RightHandSide: b
ReturnStatement:
Identifier: resultado
Nesta representação, o código é traduzido para uma árvore em que cada nó representa uma operação ou elemento do código, sem a preocupação com sintaxe de nível baixo como parênteses ou ponto e vírgula.
Diagrama de Fluxo de Controle
O CFG mostra as instruções do programa e o fluxo entre elas, considerando loops e condicionais, úteis para análise de otimização ou para geração de código.
Exemplo (CFG para o código):
[Inicio]
|
[Definir parâmetros a, b]
|
[Declarar resultado = a + b]
|
[Retornar resultado]
|
[Fim]
Neste diagrama, as setas representam o fluxo de controle, e cada bloco representa um conjunto de instruções. Ele ajuda a visualizar a ordem de execução das instruções.
Código Assembly
Exemplo (Assembly x86_64 - GCC):
soma:
push rbp ; Salva o ponteiro de base
mov rbp, rsp ; Configura o ponteiro de base
mov DWORD PTR [rbp-20], edi ; Armazena 'a' no stack
mov DWORD PTR [rbp-24], esi ; Armazena 'b' no stack
mov eax, DWORD PTR [rbp-20] ; Carrega 'a' no registrador eax
add eax, DWORD PTR [rbp-24] ; Soma 'b' ao registrador eax
mov DWORD PTR [rbp-4], eax ; Armazena resultado no stack
mov eax, DWORD PTR [rbp-4] ; Move o resultado para o registrador eax
pop rbp ; Restaura o ponteiro de base
ret ; Retorna
Cada instrução do código em C é traduzida para um conjunto de instruções de assembly que manipulam registradores e a pilha de memória para executar a função de soma.
Código de Máquina
O código de máquina é o código binário ou hexadecimal que representa as instruções diretamente executadas pelo processador. Ele é a forma final que o código assume antes de ser processado pelo hardware.
Exemplo (Código de Máquina):
55 ; push rbp
48 89 e5 ; mov rbp, rsp
89 7d ec ; mov DWORD PTR [rbp-20], edi
89 75 e8 ; mov DWORD PTR [rbp-24], esi
8b 45 ec ; mov eax, DWORD PTR [rbp-20]
03 45 e8 ; add eax, DWORD PTR [rbp-24]
89 45 fc ; mov DWORD PTR [rbp-4], eax
8b 45 fc ; mov eax, DWORD PTR [rbp-4]
5d ; pop rbp
c3 ; ret
Este código hexadecimal é diretamente interpretado pelo processador, que executa as operações de soma conforme descrito no código original em C.
Esse é o fluxo completo desde o código-fonte até o código de máquina, ilustrando cada etapa de transformação. O exemplo envolve todas as etapas que um compilador percorre para converter o código de alto nível em instruções que podem ser entendidas e executadas pelo processador. O nosso objetivo aqui é fazer o inverso, dado um código de máquina, queremos obter o código-fonte.
Exemplo Clássico de Código-Fonte
Normalmente, quando escrevemos código-fonte em linguagens como C, ele é transformado em um arquivo binário (executável) através de um processo de compilação. Durante esse processo, as estruturas e informações legíveis para humanos, como nomes de variáveis, funções, e tipos de dados, são traduzidas em instruções de máquina. Veja, por exemplo, o seguinte código em C:
#include <stdio.h>
#include <string.h>
#define true 1
#define false 0
int get_password(char *b){
if (strcmp(b, "y0u_c4n7_gu3ss_m3") == 0) {
return true;
}
return false;
}
int main(int argc, char** argv) {
char buffer[64];
printf("Welcome to your first crame problem!\n");
pass_check:
printf("What is the password?: ");
scanf("%64s", buffer);
if (get_password(buffer)) {
printf("That is correct!\n");
}
else {
printf("That is incorrect!\n");
goto pass_check;
}
return 0;
}
Neste código, temos várias partes que são legíveis, como o nome da função get_password, a variável buffer, mensagem impressa no console e a senha para conseguirmos acessar o código. No entanto, quando o código é compilado, essas informações podem ser ofuscadas ou removidas. Decore esse código fonte, pois iremos utiliza-lo em todo o mini-curso.
E se eu tiver apenas o código binário?
Agora, imagine que você não tem acesso ao código-fonte, mas apenas ao arquivo binário resultante. Como você poderia saber o que o programa faz? Este é o cenário típico em que a engenharia reversa se aplica.
Quando um programa é compilado, ele é transformado em um arquivo binário cheio de instruções de baixo nível que são difíceis de interpretar diretamente. Um exemplo de como o arquivo binário pode parecer pode ser visualizado com ferramentas como xxd, objdump, ou hexdump no Linux, que permitem visualizar o conteúdo hexadecimal do arquivo. Usando xxd, podemos ver algo assim:
00000000: 7f45 4c46 0201 0100 0000 0000 0000 0000 .ELF............
00000010: 0300 3e00 0100 0000 7010 0000 0000 0000 ..>.....p.......
00000020: 4000 0000 0000 0000 2037 0000 0000 0000 @....... 7......
00000030: 0000 0000 4000 3800 0d00 4000 1f00 1e00 ....@.8...@.....
00000040: 0600 0000 0400 0000 4000 0000 0000 0000 ........@.......
00000050: 4000 0000 0000 0000 4000 0000 0000 0000 @.......@.......
00000060: d802 0000 0000 0000 d802 0000 0000 0000 ................
Esse bloco de dados em hexadecimal representa apenas o cabeçalho do conteúdo binário do arquivo, mas sem um conhecimento profundo sobre a arquitetura do sistema e como os binários funcionam, seria muito difícil entender o que o programa faz apenas olhando para ele. No máximo você pode dizer que ele usa o Formato Executável e de Ligação (ELF).
A Importância de Ferramentas de Engenharia Reversa
Ferramentas como disassemblers (ex: objdump, Ghidra, IDA Pro) e debuggers (ex: gdb, x64dbg) são usadas na engenharia reversa para ajudar a traduzir essas instruções de baixo nível de volta para algo mais compreensível. Embora não consigamos recuperar exatamente o código-fonte original, podemos reconstruir uma boa parte de sua lógica, descobrir as funções críticas e, em alguns casos, até modificar o comportamento do software.
Aplicações
A engenharia reversa tem várias aplicações práticas:
- Segurança: Análise de malware para entender seu comportamento e desenvolver defesas.
- Compatibilidade: Estudo de software proprietário para criar versões compatíveis ou adaptáveis.
- Recuperação de código: Em situações onde o código-fonte original foi perdido, pode ser necessário reverter o binário para algo legível.
- Análise de vulnerabilidades: Descobrir pontos fracos em sistemas e protocolos, permitindo o desenvolvimento de correções.
Com essas adições, o conteúdo introduz os conceitos de engenharia reversa de forma mais clara, expandindo com exemplos e aplicações práticas. Se desejar adicionar ou modificar algo específico, posso ajustar ainda mais!
Introdução à Engenharia Reversa
Existem várias técnicas que podemos usar para realizar engenharia reversa em um binário. A primeira e mais simples é extrair as strings contidas no binário, o que pode fornecer informações úteis sobre o software.
Extraindo Strings
No contexto de engenharia reversa, as strings são sequências de caracteres ASCII presentes no binário que podem revelar mensagens, caminhos de bibliotecas, nomes de funções, e outros dados legíveis que estão embutidos no programa. Essas strings são úteis para identificar funções ou mensagens que o programa pode exibir ao ser executado.
Nos sistemas baseados em Debian, podemos usar o comando strings para extrair todas as strings de cinco ou mais caracteres de um binário. Aqui está o comando:
strings binario | less
Neste exemplo, binario se refere ao arquivo compilado, enquanto less é usado para paginar o resultado, permitindo que vejamos as primeiras linhas do output e naveguemos pelo restante.
Exemplo de Output:
/lib64/ld-linux-x86-64.so.2
puts
__libc_start_main
__cxa_finalize
printf
__isoc99_scanf
libc.so.6
GLIBC_2.7
GLIBC_2.2.5
GLIBC_2.34
_ITM_deregisterTMCloneTable
__gmon_start__
_ITM_registerTMCloneTable
Welcome to your first crack problem!
What is the password?:
%64s
That is correct!
;*3$"
GCC: (Debian 12.2.0-14) 12.2.0
O que podemos inferir?
A partir dessas strings, já podemos inferir várias coisas sobre o binário:
- Bibliotecas Utilizadas: Como
libc.so.6, que é uma das bibliotecas padrão do Linux. - Funções Importadas: Funções como
printf,scanf, eputsque são amplamente usadas em programas C. - Sistema de Compilação: A versão do GCC usada para compilar o programa, como mostrado pela string
GCC: (Debian 12.2.0-14) 12.2.0. - Mensagens do Programa: Frases como
Welcome to your first crack problem!eWhat is the password?:que nos dão pistas sobre a interação com o usuário.
Apesar de ser uma técnica útil, em arquivos binários maiores, pode ser mais difícil inferir o funcionamento completo de um programa apenas com a extração de strings. Contudo, este é um ótimo ponto de partida.
Disassemblers
Agora, podemos avançar para uma técnica mais avançada: a utilização de disassemblers. Um disassembler é uma ferramenta que converte o código binário de volta em assembly, que é uma representação mais próxima da linguagem de máquina, mas ainda compreensível para humanos.
Objdump
No Linux, a ferramenta padrão para isso é o objdump. Vamos usar o comando objdump -d -Mintel binario para ver o código assembly associado ao nosso binário. O parâmetro -Mintel especifica que queremos a sintaxe Intel, que é amplamente utilizada e mais fácil de ler para iniciantes.
Exemplo de Output:
0000000000001169 <get_password>:
1169: 55 push rbp
116a: 48 89 e5 mov rbp,rsp
116d: 48 83 ec 10 sub rsp,0x10
1171: 48 89 7d f8 mov QWORD PTR [rbp-0x8],rdi
1175: 48 8b 45 f8 mov rax,QWORD PTR [rbp-0x8]
1179: 48 8d 15 88 0e 00 00 lea rdx,[rip+0xe88] # 2008 <_IO_stdin_used+0x8>
1180: 48 89 d6 mov rsi,rdx
1183: 48 89 c7 mov rdi,rax
1186: e8 c5 fe ff ff call 1050 <strcmp@plt>
118b: 85 c0 test eax,eax
118d: 75 07 jne 1196 <get_password+0x2d>
118f: b8 01 00 00 00 mov eax,0x1
1194: eb 05 jmp 119b <get_password+0x32>
1196: b8 00 00 00 00 mov eax,0x0
119b: c9 leave
119c: c3 ret
O que podemos inferir?
Preparação do quadro da pilha:
- O valor do ponteiro de base atual é salvo no topo da pilha com
push rbp. - O ponteiro de base é configurado como o ponteiro de pilha atual com
mov rbp, rsp. - 16 bytes de espaço são alocados na pilha com
sub rsp, 0x10para armazenar variáveis locais.
- O valor do ponteiro de base atual é salvo no topo da pilha com
Movimentação de argumentos:
- O primeiro argumento, passado via registrador
rdi(presumivelmente um ponteiro para uma string de senha), é armazenado na variável local em[rbp-0x8].
- O primeiro argumento, passado via registrador
Carregamento de endereço de string constante:
- Um endereço de memória constante (
[rip+0xe88]), que parece ser uma string ou dado associado a_IO_stdin_used, é carregado no registradorrdx.
- Um endereço de memória constante (
Comparação de strings:
- O endereço armazenado em
[rbp-0x8](que é a string passada viardi) é colocado no registradorrdi. - A string constante (presumivelmente a senha correta) é colocada em
rsi. - A função
strcmp@plté chamada para comparar as duas strings.
- O endereço armazenado em
Testar o resultado:
- O retorno de
strcmp(armazenado emeax) é testado. Se o resultado for zero (test eax, eax), significa que as strings são iguais.
- O retorno de
Decisão de retorno:
- Se as strings forem iguais (
je), a função retorna1(indicando sucesso). - Caso contrário (
jne), a função retorna0(indicando falha).
- Se as strings forem iguais (
- Propósito: A função
get_passwordparece verificar se a senha fornecida corresponde a uma senha pré-definida armazenada no programa. Se a senha for correta, a função retorna1, caso contrário, retorna0. - Vulnerabilidade potencial: Dependendo de como a string constante é armazenada e acessada (provavelmente no endereço
2008), pode ser possível descobrir a senha por engenharia reversa ou inspeção de memória.
Apesar de o código assembly nos fornecer uma visão mais detalhada do que o programa está fazendo, essa linguagem ainda não é “legível” de forma intuitiva. Por isso, outras ferramentas mais avançadas podem ser usadas para melhorar a análise, como o Ghidra, que vai ser tratado como uma Seção completa.
Ghidra

Ghidra é uma ferramenta de engenharia reversa (SRE) desenvolvida e mantida pela National Security Agency Research Directorate. É um conjunto abrangente de ferramentas de análise de software que permite aos usuários examinar código compilado em diversas plataformas, incluindo Windows, macOS e Linux. Ghidra oferece recursos como desmontagem, montagem, descompilação, gráficos de fluxo de controle e suporte a scripts, além de uma série de outras funcionalidades. O melhor de tudo, Ghidra é um software gratuito e provavelmente se tornará sua principal ferramenta para engenharia reversa.
Inserindo Arquivos
Para iniciar a análise, você pode inserir um arquivo no Ghidra no formato ELF (Executable and Linkable Format), que é comum em sistemas Unix-like. Isso foi uma informação que obtemos nos métodos acima.

Utilização
Apos inserção do arquivo, podemos ver o código assembly do arquivo inserido. Vamos nos preocupar encontrar a função get_password e ver o que ela faz.

Essa função compara a senha fornecida pelo usuário com uma senha de uma variável local
("y0u_c4n7_gu3ss_m3"). Se as strings forem iguais, a função retorna 1 (sucesso). Caso contrário, retorna 0 (falha).A senha pré-definida está codificada diretamente no programa (no endereço 00102008), o que pode representa a vulnerabilidade que estamos explorando. Com senhas que não são pré-definidas, não poderiamos usar esse método
Extras da Ferramenta
Uma das grandes vantagens do Ghidra é sua capacidade de converter partes do código assembly em um formato mais legível. Isso permite que você obtenha uma visão mais clara do que o programa faz, embora nem sempre a conversão seja exata.
Por exemplo, ao analisar a função assembly acima, ele pode nos retornar o seguinte código:
bool get_password(char *param_1)
{
int iVar1;
iVar1 = strcmp(param_1,"y0u_c4n7_gu3ss_m3");
return iVar1 == 0;
}
Note que a variável iVar1 não estava presente no código-fonte original. Durante a compilação, o gcc pode gerar variáveis temporárias para facilitar o controle de fluxo e o gerenciamento de valores em assembly.
Isso levanta a questão: Ghidra sempre reproduz exatamente o código original?
- O código descompilado nem sempre corresponde ao original, pois o compilador pode otimizar o código, removendo ou reestruturando partes, tornando difícil recuperar a aparência exata do código-fonte.
E a lógica do código?
- A lógica e a funcionalidade geralmente permanecem as mesmas, mas podem haver exceções, como em casos de otimizações agressivas ou construções específicas que o descompilador não consiga interpretar perfeitamente. Mesmo assim, Ghidra tenta manter a integridade funcional do código.
Podemos também ver as funções separadamente:
| funcoes | output |
|---|---|
 |  |
Montando o código original
Usando o Ghidra, conseguimos analisar e juntar as partes de código de cada função, resultando no seguinte código “grotesco” que foi descompilado:
bool get_password(char *param_1)
{
int iVar1;
iVar1 = strcmp(param_1,"y0u_c4n7_gu3ss_m3");
return iVar1 == 0;
}
undefined8 main(void)
{
int iVar1;
undefined local_48 [64];
puts("Welcome to your first crame problem!");
while( true ) {
printf("What is the password?: ");
__isoc99_scanf(&DAT_0010205d,local_48);
iVar1 = get_password(local_48);
if (iVar1 != 0) break;
puts("That is incorrect!");
}
puts("That is correct!");
return 0;
}
Podemos observar que o código gerado está funcional, mas não está muito legível e contém elementos que podem ser otimizados. Baseado na lógica e com algumas correções, podemos converter este código para uma versão mais limpa antes de gerarmos um digrama de execução.
bool get_password(char *param_1) {
int iVar1;
iVar1 = strcmp(param_1,"y0u_c4n7_gu3ss_m3");
return iVar1 == 0;
}
uint64_t main(void) {
int iVar1;
uint8_t local_48 [64];
puts("Welcome to your first crame problem!");
while( true ) {
printf("What is the password?: ");
scanf("%s", local_48);
iVar1 = get_password(local_48);
if (iVar1 != 0) break;
puts("That is incorrect!");
}
puts("That is correct!");
return 0;
}
Explicações das mudanças:
Uso de
uint8: Como a variávellocal_48é um array de 64 bytes, podemos usaruint8_t(que é suficiente, já que 64 cabe em 255).Correção do
scanf: O uso de__isoc99_scanffoi substituído porscanf("%s", local_48);, obviamente.A troca de
undefined8parauint64No código descompilado tem a ver com a interpretação do que oundefined8representa no Ghidra e com a adaptação do código descompilado para algo mais coerente e legível em C.
O que é undefined8 no Ghidra?
O Ghidra usa o termo undefined8 quando não consegue inferir o tipo de dado com precisão. O sufixo 8 indica que o valor ocupa 8 bytes, ou seja, 64 bits. Em C, o tipo correspondente seria algo como uint64_t, que é um tipo de inteiro sem sinal de 64 bits.
No código original, o undefined8 é usado por dois motivos principais:
- Incerteza do Ghidra: Como o Ghidra não tem acesso ao código-fonte original, ele usa
undefined8como um placeholder genérico para valores que ocupam 64 bits, até que o tipo real possa ser determinado. - Arquitetura de 64 bits: A plataforma para a qual o código foi compilado pode ser uma arquitetura de 64 bits, o que faz com que muitos retornos de funções sejam padronizados como valores de 64 bits (mesmo que não precisem de tanto espaço).
Montando o Diagrama de Fluxo de Controle
Nesta seção, vamos explorar como usar ferramentas visuais para auxiliar no processo de engenharia reversa. Embora essa abordagem não seja necessária para códigos pequenos como o exemplo anterior, em projetos reais, o uso de diagramas será essencial para entender o fluxo do código e como você pode tirar proveito dele.
CodeToFlow
Uma opção é utilizar o site CodeToFlow, que gera diagramas automaticamente com base no código que limpamos anteriormente. O diagrama é criado por IA, podendo apresentar erros, mas é uma maneira rápida de obter um resultado.

Code2Flow
Outra alternativa é a ferramenta Code2Flow, que também permite a criação de mapeamentos visuais do código.

Referências
Reverse Engineering Overview Video: YouTube A comprehensive introduction to reverse engineering tools.
Ghidra GitHub Repository: GitHub The official GitHub repository for Ghidra, containing the source code and documentation.
Ghidra Official Website: Ghidra SRE The official site for Ghidra, providing downloads, documentation, and additional resources.
Ghidra Tutorial Playlist: YouTube A playlist of tutorials on YouTube that covers various aspects of using Ghidra for software reverse engineering.